Hunter.io and its API are served by a single, monolithic application built in Ruby on Rails. The first commit was performed by Antoine on March, 16th 2015, on the 4.2.0 version:

Today, more than 5 years later, we’re still working on the same repository. Fortunately, we’re on a more recent Rails version. More importantly, we’re still having fun and enjoyment working on this application on a daily basis.
Here are a few conventions, best practices and tools we’ve put in place to ensure our application remains up-to-date, clean and of course, enjoyable.
Staying up-to-date
When updates aren’t automated, it’s very demanding to commit yourself to check for outdated or unsecure dependencies on a regular basis. Hopefully, Dependabot, natively integrated into GitHub, provides a really efficient way to know when dependencies are outdated. It also gives a way to update them in a few clicks.
Dependabot regularly checks the dependencies and creates a new PR on the repository once one of them is outdated or has security issues:
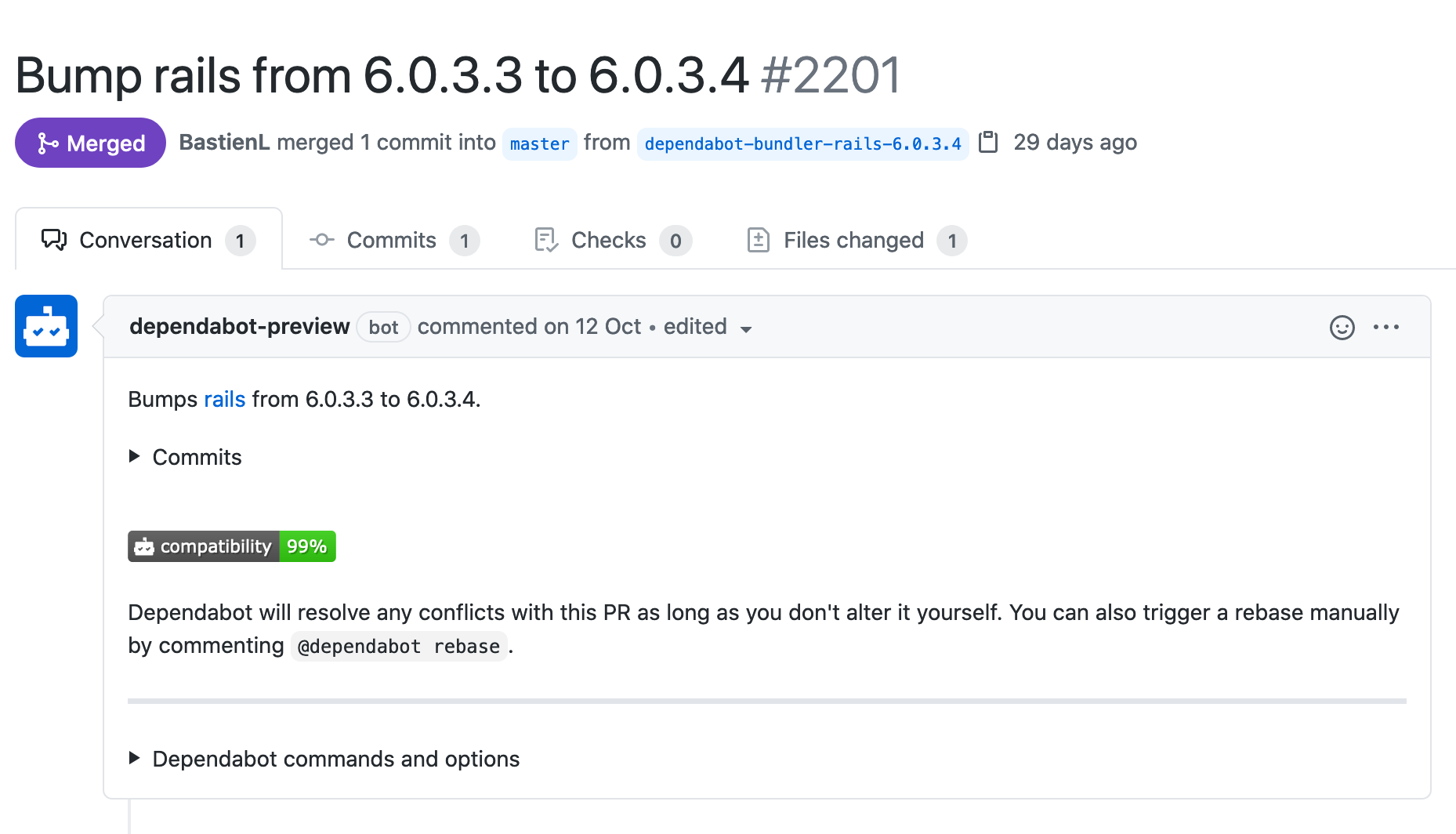
As our CI starts a new build every time a push occurs on any branch, we immediately know if the update worked and can be safely merged in production. No more reason for being late on updates. This is also how we always run the latest stable Rails version just a few days after it’s released.
We apply the same philosophy to any 3rd party or piece of software that interacts with our Rails application. Even though this may not always be automated, we make it a point of honour to run the latest versions of them. It reduces the risk of technical debt and increases a lot the developer’s enjoyment: who likes to browse outdated documentation pages?
Taking the best of Rails
Ruby on Rails is particularly known for its simplicity and the fast development it enables. This is great for folks who want to quickly turn an idea into a product. But that’s also, more surprisingly regarding the above, a framework that is still amazing after years of experience.
Let’s take Active Record callbacks as an example. A junior developer (or a senior one in a rush) might write the following code to send a welcome mail after a user has been created:
# app/controllers/users_controller.rb
class UsersController < ApplicationController
def create
user = User.create(params[:user])
# validate user creation
user.send_welcome_mail
redirect_to welcome_path
end
end
Active Records, such as our User model here, actually come with really handy callbacks. They let you attach code to certain events in the lifecycle of the models, such as creation or update.
This allows to simplify the controller code and decouple the mail sending from the user creation:
# app/controllers/users_controller.rb
class UsersController < ApplicationController
def create
User.create(params[:user])
redirect_to welcome_path
end
end
# app/models/user.rb
class User < ApplicationRecord
after_create :send_welcome_mail
private
def send_welcome_mail
# logic to send the welcome mail
end
end
This example is basic. But it illustrates how Rails can help make the controller actions super light and move the model-related logic to the right place. That’s why we try to use them as much as possible in our codebase.
Dirty attributes is also a really handy Rails feature that doesn’t come up at first, but which is really convenient for readability. Here’s what they enable, in a few verbose examples:
# app/models/user.rb
class User < ApplicationRecord
before_update :synchronize_with_cms
after_update :notify_for_email_change,
:unsubscribe_from_email_notifications
private
# Private: synchronizes the new login with the CMS before
# updating the record.
# A failure here will prevent the record to be updated.
#
def synchronize_with_cms
return unless will_save_change_to_login?
# logic to sync new login with CMS
end
def notify_for_email_change
return unless saved_change_to_email?
# logic to send the notification
end
def unsubscribe_from_email_notifications
return unless saved_change_to_subscribed?(to: false)
# logic to unsubscribe the user
end
end
In the end, a tiny set of methods makes it really clean to perform actions only when an attribute is or will be touched. No need to keep track of the previous record and compare it with the updated one, for example.
Another Active Record feature that we use a lot: Validations. Rails comes with a set of default validators (presence, uniqueness, format, etc.), that can be combined with conditions. Let’s go back to our User model:
# app/models/user.rb
class User < ApplicationRecord
validates :login,
presence: true,
uniqueness: true,
length: { in: 6..20 }
validates :avatar, presence: true, if: :premium?
end
For models that require some extended validation, Rails lets you define custom validation methods or even custom validators:
# app/models/user.rb
class User < ApplicationRecord
validate :strong_password # custom validation method
validates_with User::Validator
end
# app/models/user/validator.rb
class User::Validator < ActiveModel::Validator
def validate(user)
validate_first_name
end
end
Thanks to callbacks, dirty attributes and validations, we remove from the controllers all the models logic. They only focus on their job: receiving the request, transmitting it to the right part of the application and returning the appropriate response.
In our obsession to slim our controllers down, we also extensively use Action Controllers filters. Just like Active Record callbacks, they are methods called before, after or around a controller method. Let’s take an example from our codebase, whose goal is to prevent a Free user to use a Premium feature, attachments:
# app/controllers/attachments_controller.rb
class AttachmentsController < ApplicationController
before_action :ensure_premium_user, only: :create
def create
# logic to create the attachment
end
private
def ensure_premium_user
return if Current.user.premium?
error = "Upgrade to any Premium plan to insert attachments."
render json: { error: error }, status: :unauthorized
end
end
These are a few examples on how we follow and stick to the Rails-way of doing things. This helps us to keep a codebase that is easy read and to expand, even for newcomers.
For those who want to dig deeper, we also follow these best practices:
- We never ever write monkey patches, even though it’s seen as a Ruby great power. It just doesn’t feel right and increases the chance of maintainability issues.
- We always follow the Rails conventions, even when it requires some migration work. Credentials, introduced in Rails 5.2, or Webpacker, introduced in 6.0, are great examples.
- We use as few gems as possible.
Testing wisely
Our test suite is made up of 3 kinds of tests. They all bring their own granularity and abstraction level. As we’re not a bank and don’t send anything into space, a 100% code coverage doesn’t make sense in our context. Instead, we focus on writing the right amount of tests in regards to the criticality of a feature.
Let’s start with the highest-level type: feature tests. In this kind of tests, we want to ensure that the application, externally, behaves as expected. To do so, we rely on Capybara and Selenium. The first one starts the application and provides a DSL to interact with it, through a Selenium driver (a browser). Then, we write regular RSpec expectations:
# spec/features/users/registrations_controller_spec.rb
describe Users::RegistrationsController, type: :feature do
it "allows sign up" do
visit new_user_registration_path
expect(page).to have_content("Create a free account")
fill_in("Work email address", with: "john@mail.com")
click_on "Continue"
fill_in("First name", with: "John")
fill_in("Last name", with: "Doe")
fill_in("Password", with: "strong_password")
click_on "Create account"
expect(page).to have_current_path(users_check_your_inbox_path)
expect(page).to have_content(
"Please check your inbox to validate your account.",
)
end
end
Feature tests are really suited for Web applications as they ensure we never break any user-facing code. Unfortunately, they are slow to execute and also a bit flaky (in particular when the frontend code interacts with 3rd parties). For these reasons, it’s not possible to cover all the controllers code with them. On our end, we made the choice to limit the feature tests to mission-critical parts of the product: sign-up, suscription and most used features.
Second type of tests we practice: requests tests. Although they can also be considered as integration tests, they are a bit different than feature tests because they don’t interact with the application through HTML pages, but only through HTTP requests. They are especially useful in our case to test out all our API endpoints.
Here’s an example from our test suite:
# spec/requests/api/account_controller_spec.rb
describe Api::AccountController, type: :request do
before do
@user = create(:user)
end
it "user can get his account" do
get "/v2/account", params: { api_key: @user.api_keys.first.token }
expect(response.status).to eq 200
body = JSON.parse(response.body)
expect(body["data"]["email"]).to eq @user.email
expect(body["data"]["plan_name"]).to eq @user.subscription.plan_name
expect(body["data"]["plan_level"]).to eq @user.subscription.level
# more expectations...
end
end
Finally, the last kind of tests we have, which are also the most laborious to write, are the models tests. They can be considered as unit tests and ensure public methods from our models behave as expected, validators are well written, etc.
# spec/models/user_spec.rb
describe User, type: :model do
it { should have_many(:api_keys) }
it { should belong_to(:team) }
it { should validate_presence_of(:email) }
it "saves the primary email at creation" do
create(:user, email: "john.doe+hunter@mail.com")
expect(User.last.primary_email).to eq "john.doe@mail.com"
end
end
By testing all our mailers, models and workers this way, we make sure that all our codebase has a great test coverage.
Selecting the right test type and granularity, combined with the right tools, make testing a nice and painless part of our daily job. We’re definitely convinced that in the long run, it’s a game changer in keeping a clean application, without any dead code.
Monitoring carefully
The previous sections gave a quick overview of how we keep an up-to-date application and how we write and test code following the Rails way. But code is written to be executed, and production code needs to be monitored, right? Especially when, in our case, deployments are fully automated and occur multiple times a day. Here are the tools we use to ensure our application runs just as expected.
Sentry is the error tracking software we’ve used since the beginning of Hunter to track issues and regressions. As it’s synced with our GitHub repository, even fixing production issues becomes enjoyable:
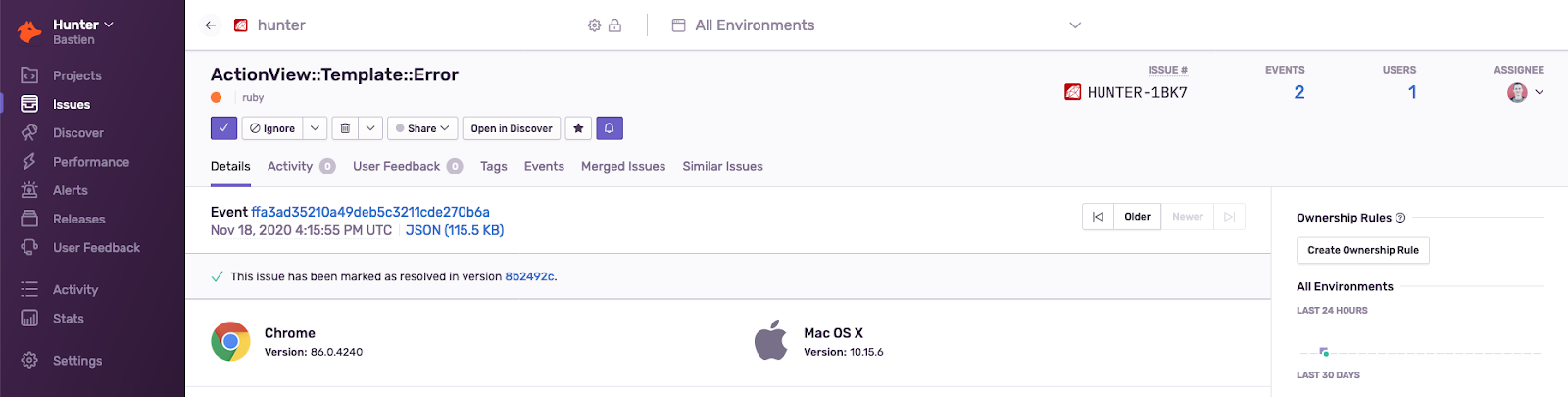
With Sentry, we make sure that we never miss any production error or regression. It also forces us to be proactive when an error occurs.
Another side of the monitoring concerns performance (speed, error rate, slow transactions, etc.). For this purpose, we trust New Relic One:
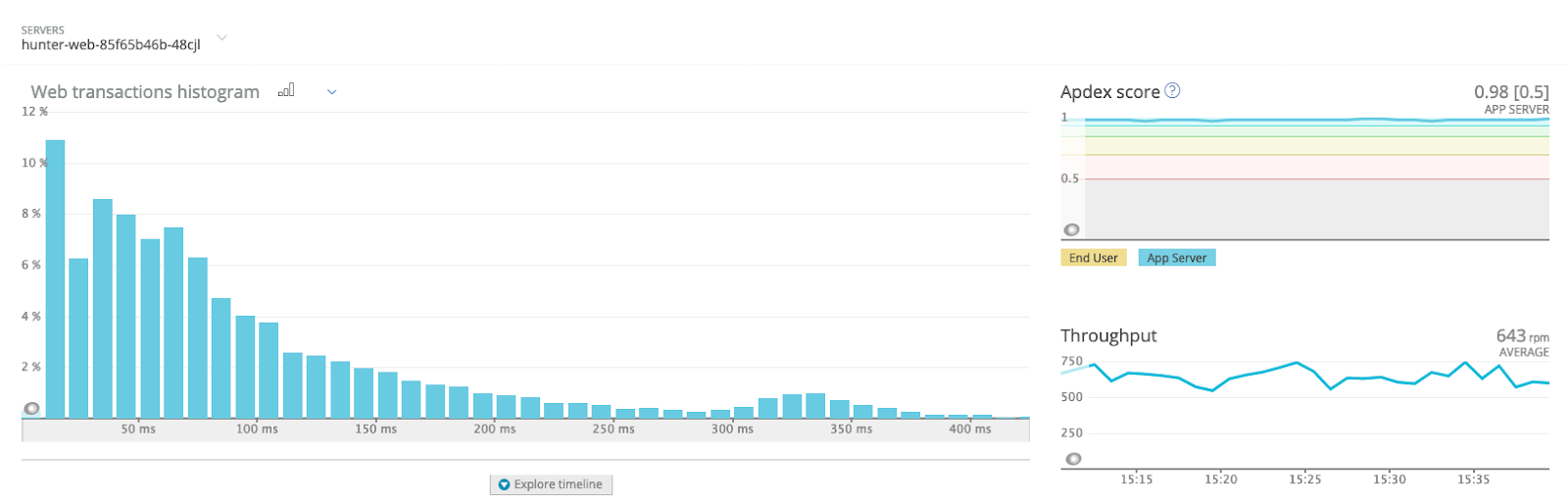
It helps us find performance regressions, bottlenecks and slow queries, as soon as they appear in production.
Conclusion
Working all day long on a single elderly and monolithic Rails application may sound boring at first. But with the right tools and best practices we’ve set up, we made this an enjoyable and thriving experience.
We’re not Rails gurus and recognize its limits: all our backend is built in Go. Though, we consider that a lot can be achieved with this framework, despite the hype on more splitted architectures and newer technologies.
If you’d would like to join us, we’re about to open a Ruby on Rails position. Subscribe here to get notified when we publish it.
We’re always open to suggestions. Just email us at engineering@hunter.io if you have feedback to share!