At Hunter, we love simplicity. As we’re a small team of 5 handling the traffic of 1 million monthly sessions, it’s necessary to have simple tools and processes we can rely on. When dealing with continuous deployment (aka “how to automatically deploy code to production, dozen times per day”), we obviously applied the same principles. This is how we did it!
The Context
Our agile team of 5 has no DevOps person, nor any System Administrator. We only have 3 environments: development (our computers), test (CI) and production (Kubernetes). Each environment is under the responsibility of everyone (as a side-effect, remote working encourages responsibilities sharing). And because we’re in 5 different countries on 2 continents, we need to be able to push code to production at any time of the day or night, weekends included.
We can translate this context in the following guidelines:
- as nobody is a DevOps expert, we need simple but solid, production-ready tools.
- as there’s no release environment, we can’t “preview” what will be pushed in production. Only safe code should be deployed.
- as we can’t be sure the rest of the team will be up when we want to release that brand new feature, nobody must be “the one who runs the deployments”.
So, how do we make this a reality?
Step 1: From development to test
Did I mention we do care a lot about simplicity? As we’re hosting our code on GitHub, the easiest way to test it was to use CircleCI. We registered a couple of containers, so we can run multiple concurrent builds and even split the tests on different containers, to speed them up.
A build on CircleCI is triggered every time code is pushed on a repository, whatever the branch is, via a GitHub webhook. The Docker image is built, the test environment is set and finally the tests are run. Nothing spectacular there. But it becomes more interesting when this happens on the [master] branch, as we’ll see in the next section.
However, there’s still an interesting point to mention. When everything’s automated, and when you deploy dozens of times a day, you can easily miss a failed build, which will block all the builds to come. Obviously, we can’t always keep an eye on what’s going on CircleCI. But we make sure to always be up on Basecamp, as it’s our main-and-only collaboration tool within the team. So we built a simple flow that posts to our ChatOps Campfire when a build finishes with something other than a success.
To do so, we set a CircleCI webhook that POSTs each build result to Zapier. On the Zapier side, we make a bit of cleanup in order to keep only relevant events:
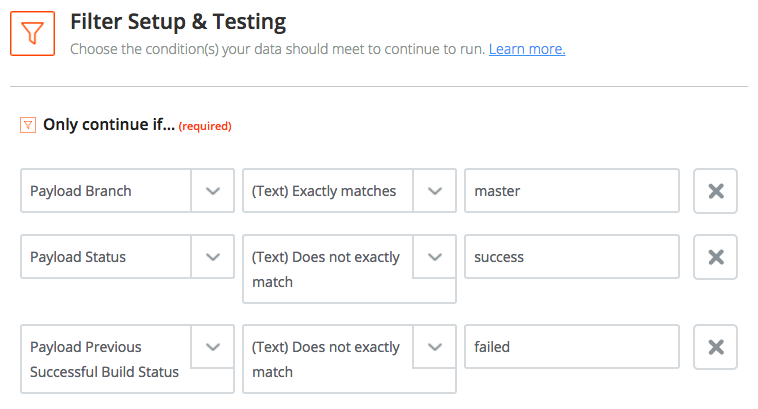
In the end, we POST back the data to Hubot, our chatbot we already talked about a long time ago.
At this point, you might ask why we don’t make CircleCI post directly to Hubot. For guys who pretend to use the simplest solutions to each problem, we seem to have added an unnecessary extra-step with Zapier. But we have a reason: unfortunately, the CircleCI webhooks cannot get headers or parameters, and we didn’t feel confident enough to version our Hubot credentials in the circle.yml file. That’s why we ended with a Zap, which brings anyway some nice features (filters, retries, etc.).
When Hubot finally receives the message through the endpoint we created for this purpose, it looks at the build status and posts to the campfire accordingly. Here is what happens when someone breaks the build:

And when you finally fix it:

With this simple system, all the team is aware when the build is broken, and the one who broke the build can’t miss it. Nice! But now, what happens when the build succeeds?
Step 2: From test to production
Remember we don’t have any release environment? This means that when a build on the [master] branch succeeds, it immediately goes to production. Scary? I’d respond yes if you don’t have enough tests (or no tests at all), but perfectly fine if your code coverage is significant. So clearly, the next part works only if most of your codebase is tested.
After our new Docker image passes all the tests, we push it to our Docker Registry, tagged with the CircleCI build number. We then wait for a few seconds, for a reason I’ll mention later in this post. And then, we do call the Hubot endpoints, responsible for deploying the different services of your app (pro-tip: using curl with “fail” argument will make it write to stderr in case of error of will make your whole deployment fail, as expected). That’s it for the CircleCI part!
Now, everything is in the hands of Hubot. He receives a message with the project to deploy and the image tag: he doesn’t need more. As all our services are managed through Kubernetes (with deployments) deploying a new version of a service translates to “replace the image used by a deployment by a new one”. And this is how Hubot achieves it:

So actually, deploying a new version of the “hunter-web” service just resides in these few lines of trivial JS code. Of course, we had to configure everything on the Kubernetes side, but that’s out of the scope of this post. And chances are that it’s possible for any Cloud Orchestrator offering an API to manage your resources.
Did you notice the request.post once the replace operation has ended. I’m sure you guessed it: it’s how we post notifications to Basecamp:
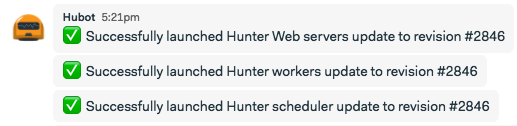
Once again, everybody in the team knows when a new version of a service has been deployed! As we wanted to, no command or manual operation was required to safely push code to production. Nice, isn’t it?
Step 3: Dealing with edge cases
Unfortunately, everything cannot be run automagically. The most common case is DB migrations.
Even if Rails has a very nice built-in DB migration tool, it seems very unlikely that you want the DB migrations to be run behind your back during each deployment (especially the destructive or locking ones). Here is our approach.
I explained sooner that before triggering the deployments, we set a sleep command. It allows us to cancel a build just before the resulting image is sent to production. So, at this step, we’ve got the latest image containing the DB migrations in our Docker repository. Why not ask Hubot to handle them?
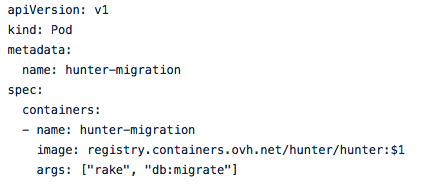
To do so, we use the Basecamp “Interactive chatbots” feature, which allows you to associate a command with an URL. Once setup, when we type !hubot hunter migrate 2850 in our ChatOps campfire, the command is posted as a JSON payload to an URL we defined: an Hubot endpoint in our case. With a regexp, we easily extract the tag and then, Hubot starts a new Kubernetes pod with the minimal requirements to run the migration:
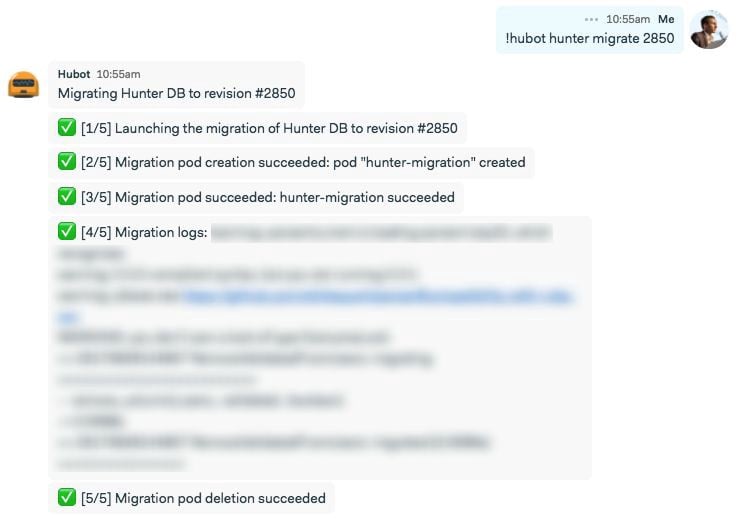
A couple of API calls to our Kubernetes master node even allow us to monitor the lifecycle of our migration pod, and post them to our favorite ChatOps campfire:
Okay, this time we had to write a command. But when dealing with a DB migration, don’t you want to? Also, we are aware that is Rails-oriented and might not work the same for other frameworks.
Conclusion
What we’ve just presented is how we deal with pushing code from our machines to production. So, in case you still wonder if 100% automated continuous deployment is possible: yes, it is!
This is how we end up pushing 10 or even 20 times a newer version of Hunter every day, without anyone doing something for this to happen. We only rely on GitHub, CircleCI, Zapier, Hubot and Kubernetes, with really few custom code.
We have to admit that it requires some prerequisites, and in particular:
- have your applications dockerized.
- manage them with a container orchestrator.
- have a good enough code coverage.
If you already match those prerequisites, you’re just a few steps away from automating your deployments.
At Hunter, we always thought continuous deployment was a crucial practice to move and iterate as quickly as possible. Even if some parts (i.e. notifications, migrations) came after, it has always been at the heart of the company. And after 3 years we can’t think about doing things differently.
And you, what’s your recipe? Do you have any improvement or advice worth sharing?