Over the last ten days, Hunter experienced two separate downtimes of around one hour each and multiple smaller downtimes of 10 minutes. The availability of our service is essential as, at any moment, hundreds of users are working and counting on us to be online. Over the last few days, we weren’t up to your expectations; we know how frustrating this must have been. Here is what we improved in our infrastructure to prevent the problem from happening again.
Our past infrastructure
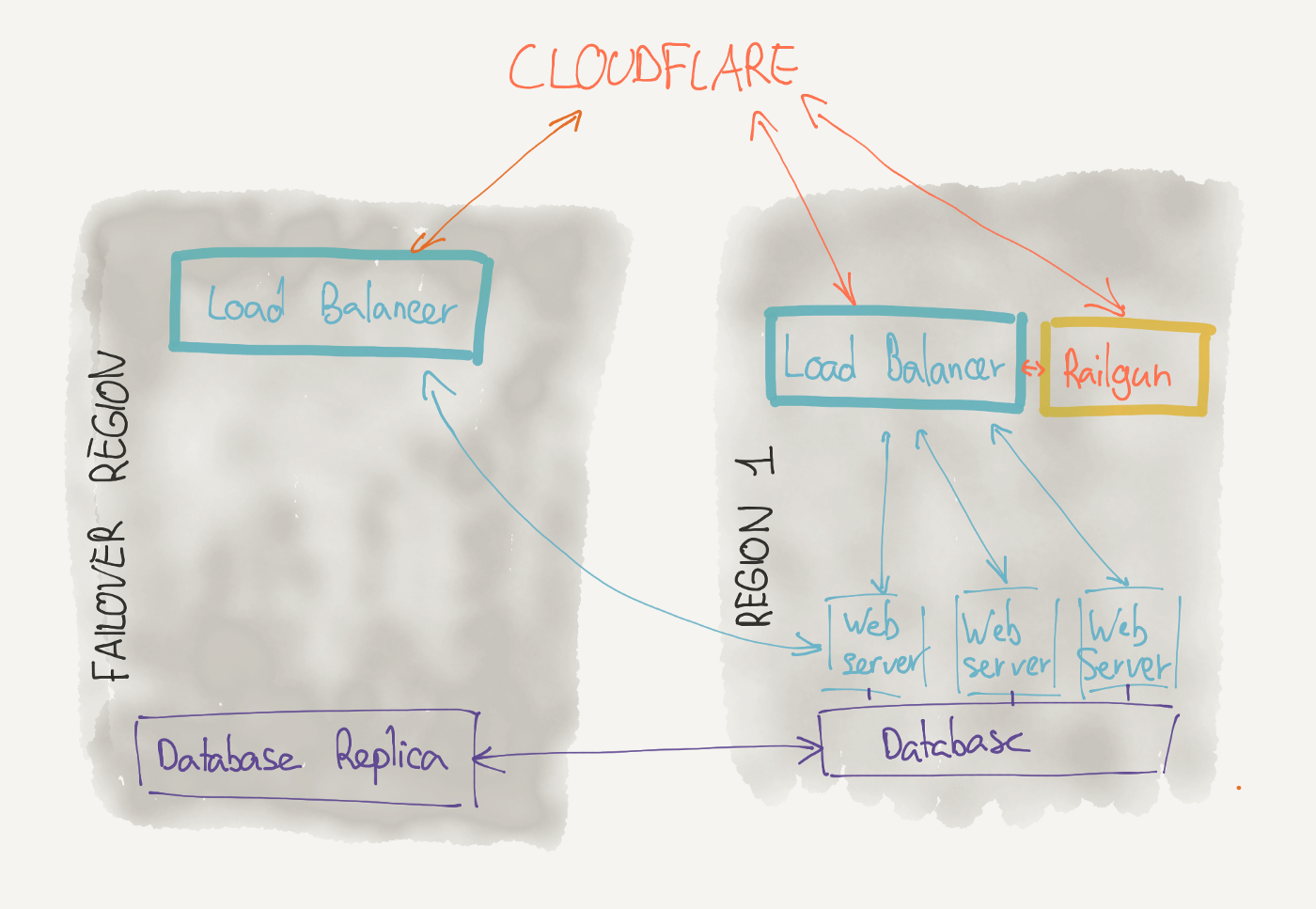
Our web servers are spread out across multiple instances. If one of them goes down, the website will stay online. But our load balancer didn’t get the same treatment. Only one server was acting as our load balancer (and Railgun server). Therefore, a downtime of the load balancer meant a downtime of all our services.
At the same time, we use one single database for our user-facing services. We back it up every day with two different methods (better safe than sorry). But in case of a server failure, we still needed to restore the entire database. We didn’t have any replica ready for use. This meant a multi-hour restoration process in case of troubles. Thankfully, for our last two big downtimes, we were able to restart the database, but it very well couldn’t have worked.
Our new infrastructure
We reworked our infrastructure to avoid having one single large point of failure. We split the load balancer into three separate servers:
- One Railgun instance
- One load balancer
- One failover load balancer in a different region
If the Railgun instance goes offline, the website stays online, and requests are only a bit slower.
If the load balancer goes offline, traffic will flow to the other region. Cloudflare handles the health checks and redirections: We know they’ll be online and working even if we’re having troubles.
Finally, the database now has another replica in a separate region. In the case of server downtime, we’ll be able to move the traffic to the replica within a few minutes. Compared to the 4 to 8 hours it would have taken before, it’s a game changer. We also migrated to another server as the previous one seemed to have electrical issues.
We’re optimistic this infrastructure will be a lot more robust and finally meet our uptime targets!